

Abstract
Disentangling data into interpretable and independent factors is critical for controllable generation tasks. With the availability of labeled data, supervision can help enforce the separation of specific factors as expected. However, it is often expensive or even impossible to label every single factor to achieve fully-supervised disentanglement. In this paper, we adopt a general setting where all factors that are hard to label or identify are encapsulated as a single unknown factor. Under this setting, we propose a flexible weakly-supervised multi-factor disentanglement framework DisUnknown, which Distills Unknown factors for enabling multi-conditional generation regarding both labeled and unknown factors. Specifically, a two-stage training approach is adopted to first disentangle the unknown factor with an effective and robust training method, and then train the final generator with the proper disentanglement of all labeled factors utilizing the unknown distillation. To demonstrate the generalization capacity and scalability of our method, we evaluate it on multiple benchmark datasets qualitatively and quantitatively and further apply it to various real-world applications on complicated datasets.
Presentation Video
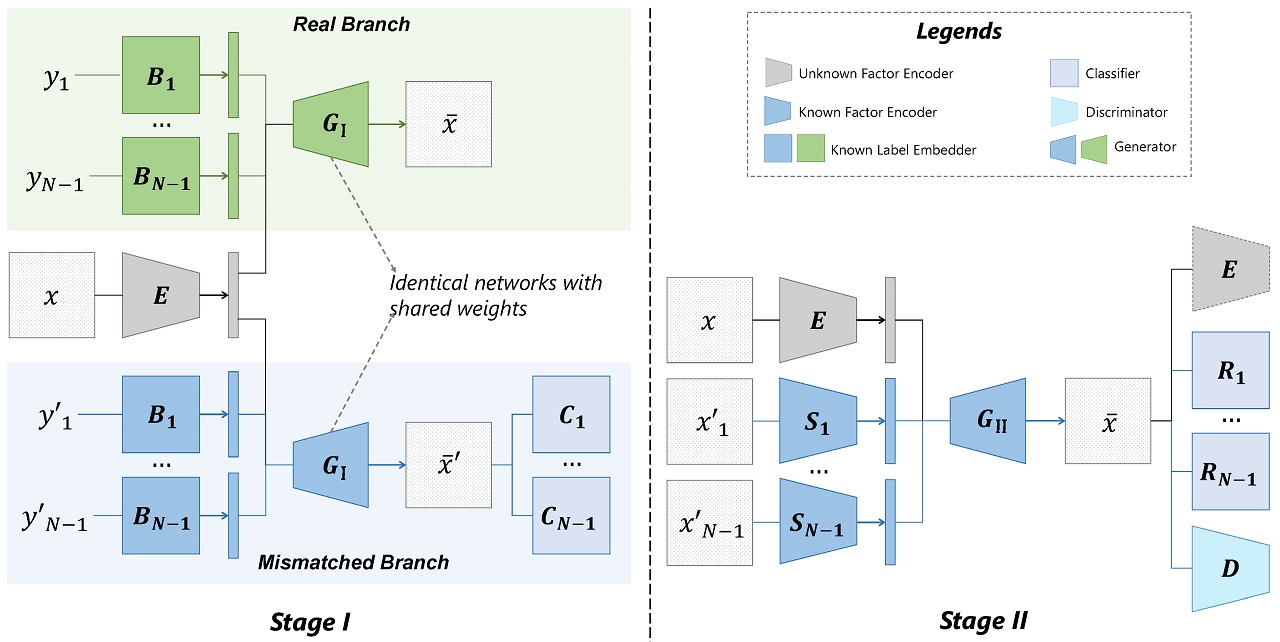
Architecture
Application 1: Anime Style Transfer.
Disentanglement of the artists’ identity (labeled) and the content (unknown) in anime images, and its application in anime style transfer.
Application 2: Portrait Relighting
Disentanglement of the lighting (labeled) and the remaining content (unknown) in portrait images, and its application for portrait relighting.
Application 3: Landmark-Based Face Reenactment
Disentanglement of the identity (labeled), the pose (labeled) and the expression (unknown) in 2D face landmarks, and its application in face reenactment.
Application 4: Skeleton-Based Body Motion Retargeting
Disentanglement of the identity (labeled), the view (labeled) and the motion (unknown) in 2D skeletons, and its application in body motion retargeting.
BibTeX
@inproceedings{xiang2021disunknown,
title={DisUnknown: Distilling Unknown Factors for Disentanglement Learning},
author={Xiang, Sitao and Gu, Yuming and Xiang, Pengda and Chai, Menglei and Li, Hao and Zhao, Yajie and He, Mingming},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={14810--14819},
year={2021}
}